13 Valutazione dei Recommender System
L’obiettivo di un recommender system dalla parte del service provider è quella di persuadere, quindi aumentare le vendite, la customer retention oppure il tempo di visione dell’utente se si parla di contenuti multimediali. Pertanto il successo di un RS può essere misurato direttamente con metriche come il conversion rate oppure con metriche indirette, ad esempio un aumento delle vendite dopo l’introduzione dell’RS.
L’obiettivo di un recommender system dalla parte dell’utente è quella di trovare item che siano buoni e che gli interessino.
13.1 Spazio di design
Lo spazio di design dipende da: - Requisiti non funzionali: adattabilità ai cambiamenti nelle preferenze degli utenti o nella disponibilità degli item, tempo di risposta del sistema, scalabilità e sicurezza riguardo la privacy degli utenti - Dominio applicativo: tipo di prodotti da raccomandare, la loro quantità, il contesto - Requisiti funzionali: qualità del RS
13.1.1 Variabili
- Fase di elicitazione: quanto un nuovo utente joina il sistema, questo deve prima imparare le sue preferenze. Questo può servire sia per un approccio collaborativo, magari chiedendo all’utente di rankare item su cui vi è tanta varianza nelle valutazioni o dove c’è disparità, o in un approccio item to item semplicemente per capire i gusti dell’utente. In alternativa si possono usare strategie esplicite o implicite, o raccogliere informazioni generali per costruire una scheda utente, e scegliere una lunghezza del profilo (numero rating) adeguata per non far ‘scappare’ l’utente.
13.2 Valutazione
Una premessa, la qualità delle raccomandazioni deve essere valutata anche in base a fattori come l’effort dell’elicitazione, il costo computazionale e il carico cognitivo richiesto all’utente. Il sistema deve collezionare abbastanza informazioni dall’utente per migliorare le raccomandazioni, dall’altro lato l’utente non vuole sforzarsi troppo per avere buoni consigli.
Le tecniche di valutazione si dividono a seconda se la valutazione si concentra sulla parte offline o online della valutazione.
13.2.1 Valutazione offline
Il sistema viene valutato con un dataset di opinioni usato come verità di fondo, e le comparazioni vengono fatte tra le opinioni stimate dal RS e i giudizi collezionati da utenti reali precedentemente. Possiamo provare a misurare diverse metriche:
Accuracy: comparazione tra raccomandazioni e un set di opinioni che funge da verità di fondo. A seconda del goal (errore, classificazione, ranking) possiamo usare diverse metriche:
Errore: Può essere calcolata usando metriche come RMSE e MAE: RMSE = \sqrt{\dfrac{\displaystyle \sum_{u , i\in T} (r_{ui} - \hat{r}_{ui})^2}{|T|}} \; \; \; MAE = \sqrt{\dfrac{\displaystyle \sum_{u , i\in T} |r_{ui} - \hat{r}_{ui}|}{|T|}} con r_{ui} il rating dell’utente u all’item i, e T il test set. Si utilizza l’ipotesi missing-at-random, ovvero si testano solo i rating osservati.
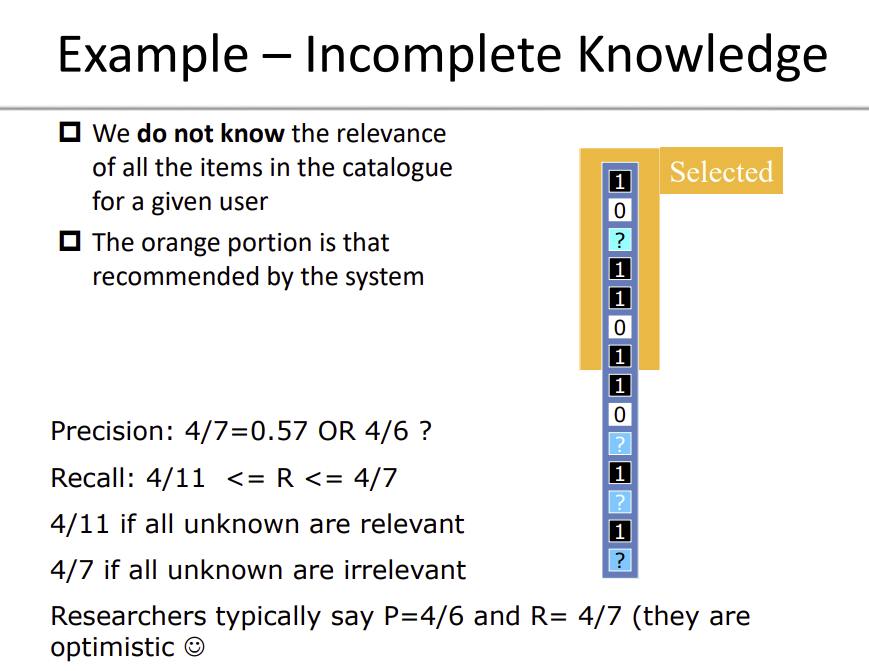
Classificazione: si può utilizzare precision e recall: precision = \dfrac{ \text{ \# relevant recommended items}}{\text{\# recommended items}} recall = \dfrac{\# \text{relevant recommended items}}{\# \text{tested relevant items}}
- Nelle metriche di classificazione si suppone che tutti i rating mancanti siano considerati come irrilevanti (All Missing As Negative Hypothesis). La precisione con l’AMAN sottostima la vera precisione calcolata anche su dati sconosciuti, che si potrebbe in alternative pensare di escludere dal calcolo delle metriche.
Le metriche di ranking, invece, vengono utilizzate per confrontare il ranking stimato con quello corretto e, pertanto, dipendono dalla disponibilità del ranking corretto. Le metriche si basano sull’NDCG, sul coefficiente di Spearman e di Kendall Tau.
Coverage: La coverage può essere intesa in due modi:
Prediction Coverage: corrisponde alla percentuale di item che possono essere raccomandati agli utenti. Ad esempio nel Collaborative Filtering gli item senza ratings oppure nel Content Based Filtering gli item senza metadata non possono essere raccomandati.
Catalogue Coverage: corrisponde alla percentuale di items che non sono sempre raccomandati agli utenti. Essa viene misurata facendo l’unione di tutti gli item raccomandati ai vari utenti e dividendola per il numero di item distinti nel dataset.
In generale la coverage può essere aumentata a scapito dell’accuratezza.
Diversity: La diversity misura il grado di diversità tra gli item raccomandati in una stessa recommendation list. Essa si calcola con la seguente formula: diversity = \displaystyle \sum_{i , j} \dfrac{𝑑𝑖𝑠𝑡𝑎𝑛𝑐𝑒(𝑖,𝑗)}{ 𝑁(𝑁−1)}dove distance(i,j) è la similarità fra i due item e N è il numero di item nel catalogo.
Anche la diversity può essere aumentata a scapito dell’accuratezza.
Essa può anche essere intesa come diversity temporale, ovvero il grado con il quale gli stessi articoli sono raccomandati sempre allo stesso utente.
Novelty: Essa misura il grado con il quale le raccomandazioni possono essere percepite come nuove dall’utente: novelty = \dfrac{\# \text{𝑟𝑒𝑙𝑒𝑣𝑎𝑛𝑡 𝑎𝑛𝑑 𝑢𝑛𝑘𝑛𝑜𝑤𝑛 𝑟𝑒𝑐𝑜𝑚𝑚𝑒𝑛𝑑𝑒𝑑 𝑖𝑡𝑒𝑚𝑠} }{\# \text{𝑟𝑒𝑐𝑜𝑚𝑚𝑒𝑛𝑑𝑒𝑑 𝑟𝑒𝑙𝑒𝑣𝑎𝑛𝑡 𝑖𝑡𝑒𝑚𝑠}}La novelty è difficile da misurare e pertanto la si può approssimare alla diversità o all’inverso della popolarità secondo la seguente formula: 𝑛𝑜𝑣𝑒𝑙𝑡𝑦 = \dfrac{\displaystyle \sum_{𝑖 \in ℎ𝑖𝑡𝑠} \log \left(\dfrac{1}{𝑝𝑜𝑝𝑢𝑙𝑎𝑟𝑖𝑡𝑦(𝑖)}\right)}{\# hits} dove hits è l’insieme degli item raccomandati e popularity(i) è una qualsiasi funzione che restituisce il grado di popolarità dell’item i.
Serendipity: raccomandazioni inaspettate e sorprendentemente interessanti per un utente che altrimenti non avrebbe mai potuto scoprirle.
Stability: grado di variazione dei rating stimati quando il profilo dell’utente viene ampliato con nuovi rating stimati. Può essere misurata con MAE o RMSE calcolata tra due stime fatte in due run diverse.
Consistency: grado di cambiamento nella lista delle raccomandazioni quando il profilo utente viene esteso con nuovi item raccomandati. La consistenza può essere vista come la diversità temporale.